


 - A How-to Guide")

Loudness Normalization: The Future of File-Based Playback

Last Updated: December 5, 2025
Today, playback on portable devices dominates how music is enjoyed. A large portion of the songs on an average music player come from online music services, obtained either through per-song purchases or direct streaming. The listener often enjoys this music in shuffle play mode or via playlists.
Playing music this way poses some technical challenges.
First, sometimes tremendous differences in loudness between selections require listeners to adjust volume.
Second, the decline in music production sound quality over the years is largely due to the loudness war. The art of dynamic contrast has nearly been lost because of the limitations of current digital systems.
Third, the potential damage to the ear caused by these loudness differences and a tendency towards higher playback levels in portable listening, especially when using earbuds.
The Three Challenges
1) Loudness Differences
In digital audio, the maximum (peak) audio modulation has a hard ceiling that cannot be crossed. Digital audio tracks are routinely peak-normalized. This results in tremendous loudness differences from track to track because the signal's peak level is not representative of its subjective loudness.
Instead, the listener perceives loudness based on the signal's average energy. With the widespread practice of peak normalization, program producers often apply severe compression, limiting, and clipping techniques to the audio.
This removes the original peaks and enables normalization, thereby amplifying the signal and increasing its average energy. This has resulted in a loudness war with significant loudness differences between newer and older material and different genres.
When older recordings are included in a playlist alongside new material, the listener experiences noticeable loudness jumps from one track to the next, requiring frequent adjustments to the playback level. The differences can be as significant as 20 dB.
The same problem arises when different musical genres are combined in a single playlist. Portable device listening is therefore not the comfortable experience it could be, and computer playback exhibits some of the same problems.
2) Restoration of Sound Quality to Our Recorded Legacy
In the practice commonly referred to as the “loudness war”, many artists, recording engineers, and record labels strive to make their recordings sound louder so they will stand out from others.
The aggressive dynamic range compression used to produce loud recordings reduces the peak-to-average-energy ratio. The effect has been that the important artistic and narrative tool of dynamic contrast has almost totally disappeared in modern music production.
The result of this pressure to be louder is that the steps of the production process, recording, mixing and mastering, produce masters that incorporate several generations of digital processing, which can cumulate clipping and alias products. This distortion is exacerbated when the product is finally encoded to a lossy medium, such as AAC.
Cumulative distortion also leads to additional significant distortion during distribution or playback. This can be fatiguing to the ear, which may turn off some listeners and even contribute to the reduced sales of contemporary music. This reduction in signal quality and dynamic range amounts to a removal of the parts of the sound which make programs sound interesting.
By switching from peak normalization to loudness normalization as a default in playback media, producers who wish to mix and master programs with wide dynamic range and without distortion can do so without fear that their programs will not be heard as loudly as the “competition”.
Loudness normalization also permits older, more dynamic material to coexist with newer recordings, allowing listeners to appreciate the sound qualities of more dynamic recordings and mix genres and recording styles.
3) Hearing Damage
High playback levels, whether accidental, chosen for personal preference, or used to overcome ambient noise, are a potential source of hearing damage. This is especially true for headphones and earbuds since their proximity to the eardrums requires relatively little power to reach damaging levels.
In the past, some European countries have attempted to address hearing damage by legislating maximum peak output levels for portable players. The net result is that it is difficult to enjoy older recordings or dynamic genres like classical music at a sufficiently loud level on these output-limited devices.
Unfortunately, this has increased pressure on mastering engineers to remove dynamic peaks from tracks to provide loud enough playback levels for the restricted peak level. Again, peak output level is not directly connected to perceived loudness. It is also not used as a predictor of hearing damage potential in international law. Instead, the integrated level over a given period should be used.
An Integrated Solution
There is a solution for problems such as inconsistent playback, the loudness war, hearing damage, and poor sound quality.
ITU Loudness Normalization
This solution is based on the widespread adoption of file-based music consumption in various formats. All playback devices and music servers are effectively computers that may analyze the average perceptual energy of a file and adjust its playback level accordingly.
For international broadcasting, the ITU-R BS.1770-2 standard for loudness measurement has recently been developed. It defines the equivalent loudness of an audio signal as its LUFS (Loudness Units relative to Full Scale) level.
BS.1770-2 does a good job in predicting subjective loudness. Loudness normalization based upon BS.1770-2 is being rolled out worldwide for television broadcast.
Apple has successfully implemented loudness normalization in its Sound Check algorithm for iTunes and supported portable players. A similar open system, known as ReplayGain, is also available for other players.
The adoption of BS.1770-2 by these systems would be advantageous, as it would ensure that music normalization is based on a single international standard for loudness measurement.
ON by Default
The listener experience will generally improve when a loudness normalization algorithm is turned on by default. This will also facilitate compliance with regulations aimed at preventing hearing loss.
Loudness normalization being on by default would also help put an end to the “loudness war” in music production.
To prevent playback devices from dropping in loudness level compared to what listeners are familiar with, we suggest a different form of system-level control, which we call Normalized Level Control.
NORM-L (Normalized Level Control)
Typical loudness normalization solutions normalize playback material to a fixed target loudness level. A separate user-adjusted volume control sets the playback level following normalization.
This is a compromise: if the target level is too low, the maximum acoustical level will not be sufficient in battery-operated devices; if it is too high, normalization will be compromised or distortion introduced.
“NORM-L” (Normalized Level Control) is a method for addressing the shortcomings of traditional fixed-target solutions. The idea behind NORM-L is that, upon playback, the listener’s volume control sets the loudness target level to which the files are adjusted.
Loudness normalization and volume control are integrated into one gain step. If this would lead to clipping of the file, the applied gain is restricted appropriately.
(See Appendix 1 for a detailed description of NORM-L).
Album Normalization
One important refinement to loudness normalization is album normalization. Although it is common nowadays to purchase music as individual songs, most artists still release their music in album format. The loudness of the album tracks has been carefully balanced by the mastering engineer to optimize the recordings' artistic impact.
In a classical symphony recording, for example, individual movements have distinct dynamic relationships with one another. If all tracks were normalized to the same target loudness, these important aesthetic properties would be lost.
Listeners often create playlists from various albums. In these cases, the loud and soft songs should be reproduced at the producer’s intended relative level; the soft songs should not be brought up to the same loudness as the loud ones.
(See Appendix 2 for further details.)
I propose that album normalization be enabled by default to satisfy the preferences of the artist, the album producer, and the majority of playback situations.
Hearing Damage Protection
In Europe, new safety requirements for A&V equipment have been published, requiring that mobile music players display a warning to users when their hearing is at risk.
By integrating these demands into NORM-L, automatic compliance with European law is achieved while providing the best possible user experience.
(See Appendix 3 for a more detailed description and suggested solutions.)
Appendices
Appendix 1: NORM-L (Normalized Level Control)
NORM-L analyzes a file’s average loudness and stores this alongside the audio as FileLUFS metadata. The file’s peak level is also stored, as FilePeak metadata. The audio content of the file remains unchanged. NORM-L can be described algebraically as follows:
Gain = min ( FaderPosition − FileLUFS, −FilePeak )
Where:
- Gain is the setting applied to playback hardware in decibels.
- FaderPosition is the physical position of the listener’s volume control. The range of this control is from a MaxFaderPosition at the physical top, down to −infinity. In other words, if MaxFaderPosition is −13 dB, when the user’s fader is at its physical maximum, the value applied to the calculation is −13 dB (see Appendix 3 for MaxFaderPosition recommendations).
- FileLUFS is the file's loudness in LUFS units.
- FilePeak is the maximum peak level of the file in decibels relative to digital full scale.
NORM-L can be described graphically as follows:
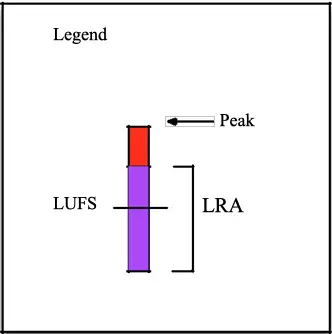
The recorded file has an average measured loudness (LUFS), indicated with a horizontal line, a maximum peak level (at the top of the red section), and a loudness range (LRA) (the purple segment), which is a measure for the macro-dynamics of a recording, the difference between the average loud and soft parts.
This figure illustrates the loudness distribution across three different genres.
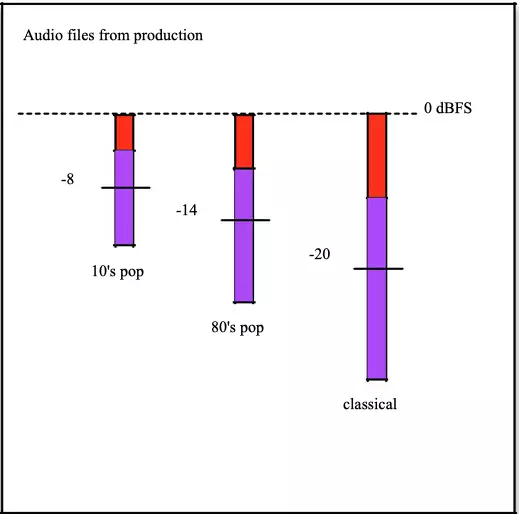
Due to the differences in the measured average loudness, it is obvious that playing these three tracks in sequence would result in loudness jumps.
Next, an example of how NORM-L solves the problem:
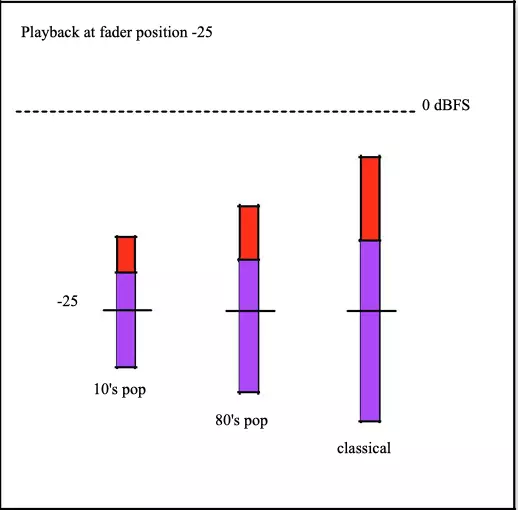
Now the three files play back at the same loudness. The first file's loudness level was -8 LUFS, and the NORM-L fader is set to -25, so this file will be attenuated by 17 dB at playback. Likewise, the -20 LUFS classical file will be attenuated by 5 dB.
Now, we raise the level control to position -20:
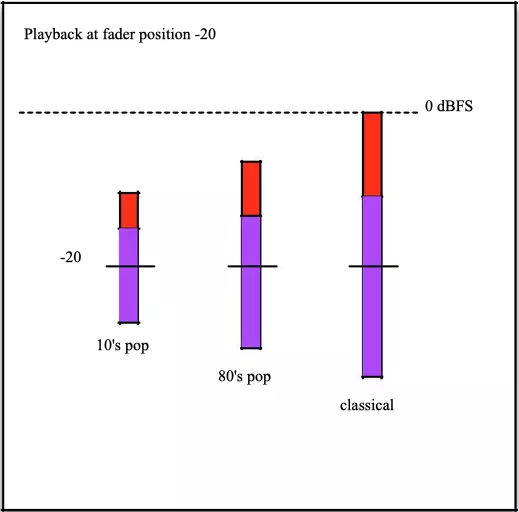
Even when increasing the NORM-L level by 5 dB, the classical material peaks at the maximum level but does not clip. The other two files still have ample headroom.
However, now the fader position is set to -15:
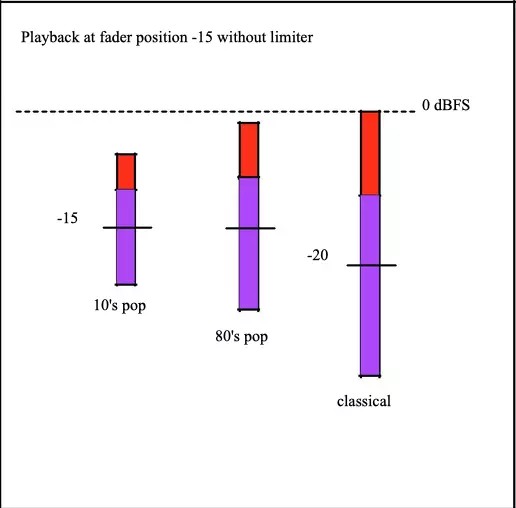
This setting would cause the classical music to clip, so NORM-L constrains its normalization to prevent this. In this case, the file will be played back effectively at -20, although the fader is set to -15. The classical music plays back 5 dB quieter than the other two examples, but is not clipped.
An alternative is to add a limiter to the playback device, as shown below:
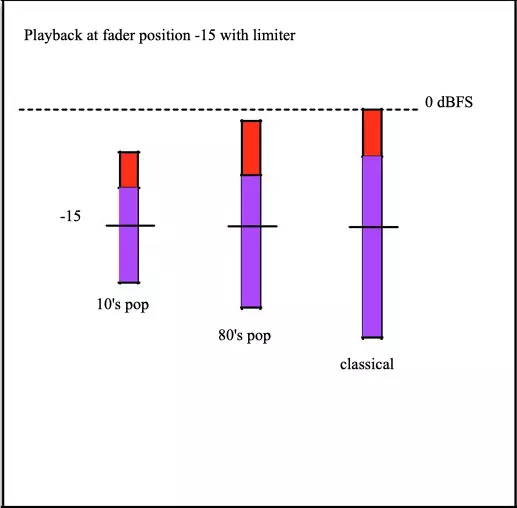
This allows the user to increase the loudness of dynamic tracks beyond the normal clipping level, but compromises sound quality as the limiter removes transients.
The vast majority of recorded music has an average measured loudness of -16 LUFS or higher. Therefore, extremely dynamic material, such as late Romantic symphonies and rare pop tracks, will encounter this clipping issue only if the listener turns the level control up too far.
For the user, this new type of level control will behave the same way they are used to. The only difference is that all songs will sound equally loud, regardless of the recordings' peak levels. The main advantage of NORM-L over fixed target systems, such as Sound Check and ReplayGain, is that normalization improves as the fader is lowered.
Appendix 2: Album Normalization
All tracks from a single album should use the loudest track's metadata value, AlbumLUFS. When available, this AlbumLUFS should be used instead of FileLUFS metadata.
When a quieter track from an album is played in sequence with other tracks, it still receives the intended lower loudness level.
To determine the maximum gain, the FilePeak level is still used. Algebraically, the NORM-L formula becomes:
Gain = min ( FaderPosition − AlbumLUFS, −FilePeak )
Appendix 3: MaxFaderPosition, Hearing Damage
In the context of our NORM-L proposal, we recommend limiting the volume control of mobile music players to a specific maximum Fader Position. The same parameter can be used to limit the maximum acoustic level of a player and headphone combination as demanded by new safety standards in Europe.
We differentiate between four situations.
a) Portable devices and other devices with sufficient headphone output level, not sold in the Euro zone.
For devices with sufficient output level, we recommend a MaxFaderPosition of −13. Well-designed players have more than sufficient analog output to allow a −13 MaxFaderPosition. A −13 max value provides effective normalization for the vast majority of music encountered today.
Furthermore, most listeners will experience a minimal change or no change in level when normalization is introduced. This will help ensure easy adoption and success of normalization.
A higher MaxFaderPosition would result in a smaller level drop, but it could lead to a large dead zone at the top of the volume control for files with low loudness. It would also lead to poor normalization when the user sets the player’s volume control to maximum, and the headphone output is connected to a line input feeding an external amplified speaker or a car system.
b) Lower-cost MP3 players and other devices with lower output level and headroom, not sold in the Euro zone.
In this case, we recommend the lowest possible value that still produces sufficient acoustical output through the included earbuds. Values above −13 result in inadequate normalization at higher fader settings.
As an alternative, manufacturers should consider enhancing the headphone output capability of their players to provide an adequate level and sufficient peak headroom.
c) Line or digital outputs and wireless connections on mobile players, media systems and personal computers.
When a mobile device is placed in a docking station, audio is often played via a separate digital or analog line output. This output is connected to an amplifier, which features its own volume control that serves as the primary volume control for the sound system.
NORM-L offers no advantage here, and we advise using a fixed target level of −23 LUFS, preferably (based on EBU Tech Doc 3344).
Although this may seem like a low value, the connected amplifiers typically have more than sufficient gain to compensate, and the advantage is that even most classical music will be properly loudness normalized without clipping.
Another advantage is that when switching to modern AV systems operating at the same target level, the user will not experience a loudness jump.
d) Hearing Loss Protection in the Euro zone.
For hearing loss prevention, international laws prescribe the use of A-weighted intensity measurement and equivalent exposure over time (the dose).
In Europe, a CENELEC working group, in consultation with the European Committee, has published a standard for portable music playback devices, including their accompanying earbuds. The standard requires a safety warning message to be displayed when the intensity exceeds 85 dB SPL A-weighted (dBA).
The listener must actively confirm the message before they are allowed to play at higher levels, and under no circumstances is playback above 100 dBA permitted. Conventionally, the 85 dBA limit is enforced by measuring the average energy over a 30-second window in real time.
As a result, loud passages in dynamic recordings (such as classical music) may unnecessarily trigger the warning. The CENELEC group was aware of this and allows that “if data is available of the average level of the whole song, the message may also be given in case the integrated average level exceeds 85 dBA.”
While loudness normalization is being performed, hearing loss prevention can be accomplished by calculating a per-track WarningFaderPosition and MaxFaderPosition that take into account the file’s A-weighted level.
By measuring and storing FileDBA (the integrated average A-weighted level), in addition to the FileLUFS loudness level, the same metadata mechanism used for loudness normalization can also be used to produce hearing damage warnings and operating restrictions that comply with EU law.
Using FileDBA instead of a conventional real-time measurement has several benefits: the user can be warned of excessive loudness at the beginning of a track, rather than being interrupted in the middle. Additionally, the potential for hearing damage from dynamic content, such as classical music, is assessed on a long-term basis in accordance with hearing loss protection standards and laws.
The per-file fader position at which the device must show a warning and the level at which the device limits its output can be described algebraically as follows:
WarningFaderPosition = 85 − IECLevel + RefnoiseLUFS − FileDBA + RefnoiseDBA
MaxFaderPosition = 100 − IECLevel + RefnoiseLUFS − FileDBA + RefnoiseDBA
Where:
- WarningFaderPosition is the fader position above which the player must display a warning in conformance with EN 60065.
- MaxFaderPosition is the physical maximum of the device’s fader used for the duration of the file.
- IECLevel is the EN 50332 measured acoustical level of a portable device at its maximum gain (NORM-L in bypass) with its standard headphones in dB(A) SPL.
- RefnoiseLUFS is the measured loudness of EN 50332 single-channel reference noise. A value of −13 LUFS should be used here.
- FileDBA is the A-weighted level of the file’s loudest channel.
- RefnoiseDBA is the A-weighted level of the EN 50332 reference noise. A value of −12.6 dBA should be used here.
Example: Suppose a device can produce a maximum acoustic output of 104 dBA from factory earbuds when playing the reference noise. While playing a file whose loudest channel measures −14.6 dBA,
MaxFaderPosition = 100 − 104 − 13 + 14.6 − 12.6 = −15 would need to be used to prevent the output from exceeding the 100 dBA hearing-loss protection limit.
Portable players may include an equalizer. If present, EN 50332 requires that this equalizer be adjusted to maximize the sound pressure level and that this setting be used to establish the 100 dBA limit.
Because the impact of an equalizer on sound pressure level is content dependent, when the equalizer is engaged, it’s no longer possible to accurately determine the 85 dBA and 100 dBA thresholds based on FileDBA.
To meet EN 50332 requirements, a system must account for the effect of EQ settings. This can be done by conservatively biasing WarningFaderPosition and MaxFaderPosition to ensure that in the presence of EQ, the thresholds are never exceeded.
Alternatively, manufacturers may choose to design the equalizer such that it never boosts the sound level at any frequency; to achieve a boost, everything else is cut. An additional advantage of the latter EQ method is that the system cannot overload before the volume control.
By following this rule, the portable audio device automatically complies with the maximum acoustic level of 100 dBA as specified in EN 60065, and any additional available headroom is used to improve normalization effectiveness.
Note that NORM-L in this case should not be defeatable by the user, or the device would become illegal. In EU countries, where device output has so far been limited to comply with the law, older recordings and uncompressed genres, such as classical music, can once again be played with adequate loudness.
Appendix 4: Loudness Analysis
When or where should the loudness be analyzed in the file? Ultimately, this is a decision made by player manufacturers. Here are some options:
- by the record label or mastering house
- at the point of sale (iTunes Store or other web store)
- in the media server (iTunes in the context of Apple products, for instance)
- in the portable player itself.
Metadata from an unknown source cannot be trusted. Unless the source is secure (as with iTunes), we advise letting the portable player conduct the analysis itself, as it must be performed once. Battery power consumption may be a reason to perform loudness normalization of content outside the player. Again, this is a decision ultimately made by manufacturers.
Noise Reduction Technology (Primer)
The intelligibility of human speech plays a crucial role in communication, serving as both a measure of comfort and a gauge of comprehension.
The quality and intelligibility of speech are not only determined by the physical characteristics of the speech itself, but also by communication conditions and information capacity, as well as the ability to derive information from context, mimics, and gestures.
When discussing intelligibility, it is important to understand the difference between real and recorded speech.
During a real conversation, a person can recognize surrounding sounds and concentrate on another person's speech, thereby filtering out the desired information from various audio environments. Therefore, a human's ability to identify and filter sounds significantly enhances speech intelligibility and comprehension, even in noisy environments.
Listening to recorded speech is different. The recording equipment doesn’t focus on specific audio streams (unless it is a specialized shotgun microphone) and impartially records everything in the audio spectrum. As a result, we receive a “flat picture” of all recorded sounds, which often makes the speech unintelligible, quiet and buried in the noise.
Additional reasons why speech recordings may be indistinct and distorted include technical limitations of recording equipment, poorly placed or defective microphones, and objective difficulties in recording high-quality, “clean” sound.
As audio recording technologies have gained wider use since the mid-20th century, the demand for audio processing and noise reduction has also increased exponentially. Even now, with audio equipment offering greater quality, the need for noise suppression remains of utmost importance, especially in areas such as security and law enforcement.
Police departments, the military, and national security services primarily use overt and covert recordings of speech, which can be a crucial element in investigations and intelligence operations. Needless to say, an audio recording may sometimes be the only evidence of a security threat or crime, and therefore it may become a key element in the case analysis or subsequent court trial.
In these cases, it is important for speech to be clear and easily understandable to ensure no vital information is lost. Moreover, the intelligibility of audio evidence is essential for court proceedings, as it might otherwise be excluded from consideration.
Improving the intelligibility of a speech signal, reducing noise, and compensating for distortions are primary tasks of noise reduction technology, which is currently available through various software and hardware products.
This research paper aims to discuss the fundamentals of noise-reduction technology, its methods, and its objectives.
Classification of Audio Hindrances
To understand the basics of noise reduction technology and successfully apply its methods in practice, it is essential to recognize the various audio hindrances, their differences, and their unique characteristics.
Generally, all audio disturbances are divided into two main categories: noise and distortion. If we consider an original human speech recording a helpful signal, all additional information that decreases its quality is noise. Everything that changes the original useful signal itself is considered distortion.
Noises are characterized primarily in the time and frequency domains.
In the time domain, noises can be:
- Continuous, slowly changing noises, like the sound of an office, industrial equipment, wind, traffic, hiss of an old record or a bad phone line.
- Discontinuous, repeated, usually tonal noises like honks, beeps or bells.
- Pulse-like, abrupt, usually unharmonious and sometimes loud noises like clicks, taps of the steps, gunshots, bangs and thumps.
In frequency domains, noises can be:
- Broadband noise, present at many frequencies, such as background hiss or fizzing sounds.
- Narrowband noises, which represent a set of certain frequencies, are fairly stable tonal sine waves: drones, power-supply hums, equipment hindrances (drills, chainsaws), and machinery engine noises.
Distortions are modifications of the useful speech signal that decrease its quality. When distortions occur, parts of the whole speech signal change and become new, and sometimes sound unacceptable.
Typical distortions at the acoustical level are reverberation and echo effects.
Distortions also occur when the acoustic signal (speech) transforms into an electrical signal and meets various technical limitations, such as:
- Poor frequency response of the recording equipment or the communication channel causes filtering of the audio signal.
- Loss of useful data caused by a narrow dynamic range.
- Overflow effect, which occurs when the amplitude of the acoustic signal is higher than the amplitude that a microphone can process.
- Total harmonic distortions, which are the additional tones (harmonics) that mask real signal components and make it indistinct and incomprehensible.
- Recording audio data in a compressed lossy format.
Generally, noise-reduction technology helps address such distortions; however, some types of distortion may destroy useful information and cannot be restored during subsequent signal processing.
Noise Reduction Methods
The process of noise reduction raises many questions across different fields of science (digital signal processing, acoustics, psychoacoustics, and physiology) and engineering (programming, construction, etc.).
Its effectiveness depends on the correspondence between the processing method and the type of audio interference. Each digital filtration method is more effective for a specific kind of noise.
This is why it is necessary to know, at least in general, which types of audio hindrances affect an audio recording, so that an appropriate processing method can be chosen. One can identify the audio hindrance in the recording by either the specific sound of the noisy signal or by analyzing its spectrum and waveform.
Various noises and distortions may sometimes sound similar; therefore, the most popular method for identifying an audio hindrance is to analyze the spectrum and waveform. As noise characteristics usually change over time, it is necessary to use a specialized processing method that automatically adjusts to them.
Digital filtration algorithms that can adjust to a specific type of audio distortion are called adaptive filtration algorithms.
SpeechPro Inc. extensively uses adaptive algorithms of a new generation in its hardware and software products:
- Adaptive broadband filtration
- Adaptive inverse filtration
- Frequency compensation
- Impulse filtration
- Dynamic processing
- Stereo processing
Adaptive Broadband Filtration
Adaptive broadband filtration is based upon an adaptive frequency algorithm. This algorithm is designed to suppress broadband and periodic noise caused by electrical pickups or mechanical vibrations, room and street noise, and interference from the communication channel or recording equipment. You may hear these noises as hums, rumblings, hisses, or roars.
The broadband filtration method typically consists of two processing procedures: adaptive spectral noise subtraction, which enhances the speech, and adaptive background extraction, which separates the background acoustic environment from the useful signal. It is nearly impossible to remove such noises using other methods because they span the entire spectrum and overlap with the speech signal.
Recorded conversation between two people in the noisy street:
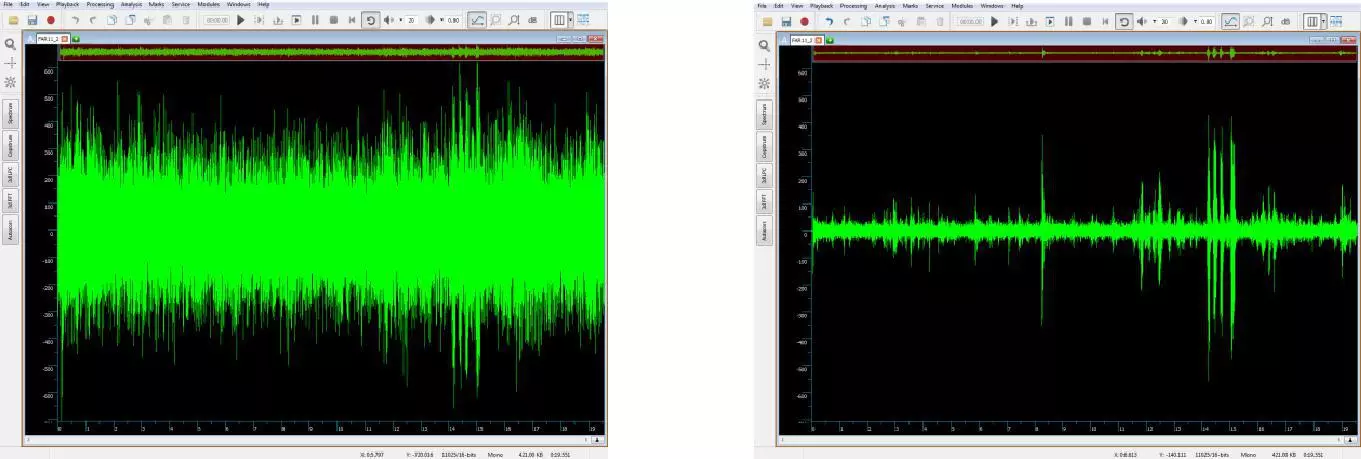
Adaptive Inverse Filtration
Adaptive inverse filtration is based on the adaptive spectral correction algorithm, also known as adaptive spectral smoothing. It suppresses strong periodic noise from electrical pickups or mechanical vibrations, thereby recovering speech and equalizing the signal.
It amplifies weaker signal components while suppressing stronger ones. The average spectrum, therefore, tends toward a flat spectrum, enhancing the speech signal and improving its intelligibility. Broadband noises, however, usually become stronger, making signal perception less comfortable.
This means that you should strive to strike a balance between noise reduction and speech perception.
Frequency Compensation
Frequency compensation uses the Widrow–Hoff adaptive filtering algorithm of one-channel adaptive compensation. It is most effective for narrowband stationary interferences.
The filter adjusts smoothly, maintaining speech quality. The frequency compensation in this process also provides adaptive time-domain compensation. It enables the removal of both narrowband stationary interference and regular interference (vibrations, power-line pickups, electrical device noises, steady music, room, traffic, and water noises, reverberation, etc.).
The main advantage is its ability to preserve the speech signal better than other filters do. Since audio interference may be removed only partially in some cases, it is possible to use frequency compensation multiple times.
Power-line buzz masks the conversation between two people:
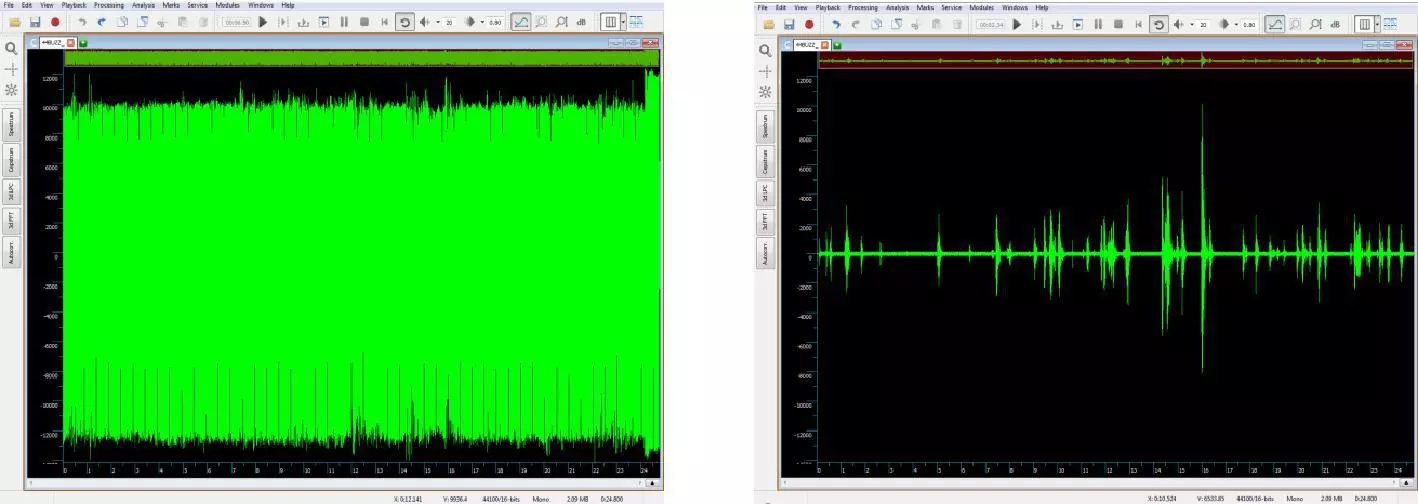
Adaptive Impulse Filter
An adaptive impulse filter automatically restores speech or musical fragments distorted and masked by various pulse interferences, such as clicks, radio noise, knocks, and gunshots. Adaptive impulse filtering algorithms enhance the signal quality by suppressing strong signal impulses, thereby unmasking the useful audio signal and improving its intelligibility.
During impulse filtration, it substitutes impulses with smoothed and weakened interpolated signals. If the algorithm does not detect an impulse, it leaves the fragment intact. It also does not suppress tonal interferences and broadband noises.
Tapped phone conversation interfered by another line's beeping:
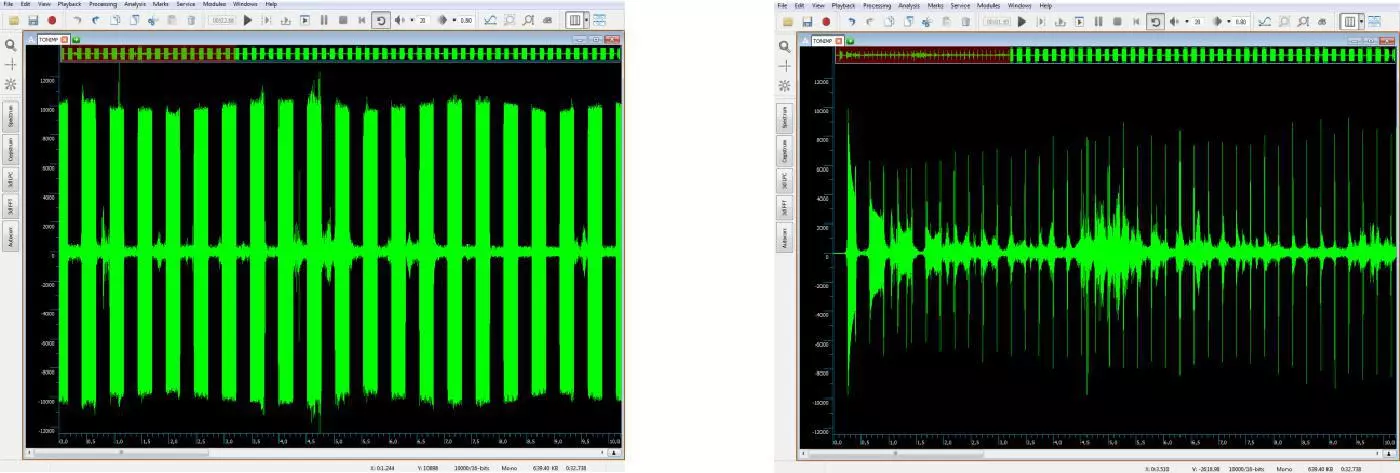
Dynamic Signal Processing
Dynamic signal processing enhances the intelligibility of speech when the signal fragments differ significantly in level, particularly in cases such as resonant knocks (i.e., long impulses) and room noises. Dynamic processing algorithms enhance and refine the audio signal, suppressing powerful impulses and clicks, and reducing listener fatigue in long audio recordings.
Stereo Filtration
Stereo filtration is one of the latest innovations in noise reduction technology. In some cases, noise removal can be achieved using dual-channel audio information monitoring and dual-channel adaptive filtering (stereo filtering). This method, however, is more sensitive to the audio recording process and its quality because it requires a more accurate use of two or more microphones.
There are two methods of stereo filtration available: two-channel signal processing and adaptive stereo filtering.
In the first case, the sound in each channel is processed independently. In the second case, data acquired from one channel (the reference channel) is used to filter the signal in the second channel (the primary channel).
Stereo filtration effectively reduces background music and crowd noise, thereby enhancing the useful speech signal in recordings from large rooms, such as halls, restaurants, and theatres.
SpeechPro’s Product Line Has The Solution
Some key elements of SpeechPro’s expert systems include a unique sound-cleaning software application that won first prize in an audio enhancement contest organized by the Audio Engineering Society (AES) in 2008.
SpeechPro’s expert systems were highly evaluated by world-class forensic audio analysts and adopted by law enforcement agencies throughout the USA, Europe, and Latin America.
Automatic systems are compact, real-time noise-filtering and speech-enhancement devices that can be of great value to police, surveillance teams, private investigators, forensic labs, and other law enforcement agencies. They can be used in real time to improve sound and speech quality during recording or listening in field conditions.
Moreover, SpeechPro’s hardware solutions can be of great interest to audio engineers working in mobile audio processing and broadcasting, particularly for “live” mastering of interviews and reports.
Being mobile and compact, these devices are effective against communication channel interference, office equipment, industrial and vehicle engines, street traffic, environmental noise, background music, hiss and rumble, reverberations, and echo effects. They also provide methods for stereo processing using algorithms based on the reference channel.
R&D solutions for noise reduction are presented as cross-platform libraries, automatic/manual algorithm adjustment, and real-time/post-processing embedded/workstation implementations.
SpeechPro’s SDK noise reduction features include:
Broadband Noise Filter/Canceller; Equalizer (EQ), Graphical EQ, Adaptive EQ, Parametric EQ; Dynamic Range Control, Sound Level Limiter; Automatic Gain Control; Level Control, Speech Level Enhancement; Punch & Crunch Dynamics Processing; Acoustic Shock Protection, Adaptive Shock Attenuator/Limiter [DSP-factory]; Harmonic Reject Filter: Adaptive & Fixed COMB; Hiss Filtration.
Remember the Principles of Noise Reduction
Generally, noise reduction methods were developed to extract the useful signal from various types of audio disturbances.
The noise-reduction standard approach is based on the principle of removing unnecessary extraneous sound components and restoring distorted parameters to their typical values.
The most typical noise suppression goal is useful signal unmasking—suppressing noisy signal components in areas where the hindrances are strong and the useful signal is weak, and enhancing those components where the useful signal is at its maximum.
Thus, the basic principles of noise reduction technologies are:
- Unmasking the useful speech signal in time and frequency domains, considering psychoacoustic properties of human speech hearing.
- Removing various types of background noise to reduce fatigue during listening.
- Decreasing the signal's passband frequency and removing low-frequency drones and high-frequency hisses.
- Smoothing the high peaks and reducing the audio signal amplitude during pauses without speech.
- Removing or decreasing pulse-like interference amplitude and other intense outside sounds.
- Removing regular, slowly changing hindrances: music, traffic, and industrial noises; decreasing reverberation (echo effects).
- Smoothing signal spectrum.
- Additional subtraction of narrowband interferences.
- Removing additive broadband noises (tape, radio, phone and microphone hiss).
